Resultados da pesquisa para 'Google'
-
Resultados da pesquisa
-
Tópico: Shodan Search Engine – O Que É?
Shodan Computer Search Engine – Saiba tudo sobre!
 O Shodan é um mecanismo de buscas que permite ao usuário encontrar tipos específicos de computadores (webcams, roteadores, servidores, etc.) conectados à Internet, usando uma variedade de filtros.
O Shodan é um mecanismo de buscas que permite ao usuário encontrar tipos específicos de computadores (webcams, roteadores, servidores, etc.) conectados à Internet, usando uma variedade de filtros.Alguns também o descreveram como um mecanismo de pesquisa de banners de serviço, que são metadados que o servidor envia de volta ao cliente.
Isso pode ser uma informação sobre o software do servidor, quais opções o serviço suporta, uma mensagem de boas-vindas ou qualquer outra coisa que o cliente possa descobrir antes de interagir com o servidor.
O Shodan coleta dados principalmente em servidores web (HTTP / HTTPS – porta 80, 8080, 443, 8443), bem como FTP (porta 21), SSH (porta 22), Telnet (porta 23), SNMP (porta 161), IMAP (portas 143, ou (criptografada) 993), SMTP (porta 25), SIP (porta 5060), e Real Time Streaming Protocol (RTSP, porta 554). O último pode ser usado para acessar webcams e seu fluxo de vídeo.
Foi lançado em 2009 pelo programador John Matherly, que, em 2003, concebeu a ideia de procurar dispositivos ligados à Rede Mundial de Computadores. O nome Shodan é uma referência a SHODAN, um personagem da série de videogame System Shock.
Background
O site de buscas Shodan começou como projeto de estimação de John Matherly, baseado no fato de que um grande número de dispositivos e sistemas de computador estão conectados à Internet.
Usuários do Shodan são capazes de encontrar sistemas, incluindo semáforos, câmeras de segurança, sistemas de aquecimento doméstico, bem como sistemas de controle para parques aquáticos, postos de gasolina, estações de água, redes de energia, usinas nucleares e ciclotrões aceleradores de partículas; pouca segurança.
Muitos dispositivos usam “admin” como nome de usuário e “1234” como senha, e o único software necessário para se conectar a eles é um navegador da Web.
Cobertura da mídia
Em maio de 2013, a CNN Money divulgou um artigo detalhando como o SHODAN pode ser usado para encontrar sistemas perigosos na Internet, incluindo controles de semáforos. Eles mostram capturas de tela desses sistemas, que forneceram a faixa de aviso “A MORTE PODE OCORRER !!!” ao conectar-se.
Em setembro de 2013, a Shodan foi mencionada em um artigo da Forbes alegando que foi usada para encontrar as falhas de segurança nas câmeras de segurança TRENDnet.
No dia seguinte, a Forbes seguiu com um segundo artigo falando sobre os tipos de coisas que podem ser encontrados usando o Shodan.
Isso incluiu caminhões da Caterpillar cujos sistemas de monitoramento a bordo eram sistemas de controle de aquecimento e segurança acessíveis para bancos, universidades e gigantes corporativos, câmeras de vigilância e monitores cardíacos fetais.
Em janeiro de 2015, o Shodan foi discutido em um artigo da CSO Online abordando seus prós e contras. De acordo com uma opinião, apresentada no artigo como a de Hagai Bar-El, a Shodan realmente oferece ao público um bom serviço, embora destaque aparelhos vulneráveis. Essa perspectiva também é descrita em um de seus ensaios.
Em dezembro de 2015, várias agências de notícias, incluindo a Ars Technica, relataram que um pesquisador de segurança usou o Shodan para identificar bancos de dados acessíveis do MongoDB em milhares de sistemas, incluindo um hospedado pela Kromtech, desenvolvedora da MacKeeper.
Uso
O site Shodan rastreia a Internet para dispositivos acessíveis ao público, concentrando-se em sistemas SCADA (controle de supervisão e aquisição de dados).
Shodan atualmente retorna 10 resultados para usuários sem uma conta e 50 para aqueles com um. Se os usuários quiserem remover a restrição, eles devem fornecer um motivo e pagar uma taxa.
Os principais usuários do Shodan são profissionais de segurança cibernética, pesquisadores e agências de aplicação da lei. Embora os cibercriminosos também possam usar o site, alguns normalmente têm acesso a botnets que poderiam realizar a mesma tarefa sem detecção.
Ferramentas de pesquisa automatizadas
SHODAN Diggity – Fornece uma interface de digitalização gratuita e fácil de usar para o mecanismo de busca SHODAN.
Pesquisa em massa e processamento de consultas SHODAN podem ser realizadas usando o SHODAN Diggity (parte do SearchDiggity, a ferramenta de ataque gratuita do mecanismo de busca do Bishop Fox). A ferramenta gratuita fornece uma interface de digitalização fácil de usar para o popular mecanismo de busca de hackers através da API SHODAN.
O SHODAN Diggity vem equipado com uma conveniente lista de 167 consultas de pesquisa prontas em um arquivo de dicionário pré-fabricado, conhecido como SHODAN Hacking Database (SHDB).
Este dicionário ajuda a direcionar várias tecnologias, incluindo webcams, impressoras, dispositivos VoIP, roteadores, torradeiras, switches e até SCADA / Sistemas de Controle Industrial (ICS), para citar apenas alguns.
Monitoramento contínuo via feeds RSS
Os Alertas Hacking SHODAN são feeds RSS de vulnerabilidade ao vivo que extraem regularmente os resultados de pesquisa do mecanismo de pesquisa SHODAN.
As ferramentas defensivas gratuitas do Bishop Fox incorporam os dados do SHODAN em seus alertas de defesa, utilizando o recurso para transformar os resultados de pesquisa do SHODAN em feeds RSS, anexando & feed = 1 aos URLs de consulta comuns do SHODAN. Por exemplo: https://www.shodanhq.com/?q=Default+Password&feed=1
Esses alertas RSS gratuitos podem ser utilizados para realizar o monitoramento contínuo dos resultados do SHODAN para quaisquer novas exposições de vulnerabilidades relacionadas às organizações.
Eles fazem parte da suíte de ferramentas defensivas gratuitas do Projeto do Google Hacking Diggity, que formam um tipo de sistema de detecção de intrusões para o mecanismo de busca de hackers (incluindo resultados do SHODAN, Google, Bing, etc.).
Cultura popular
Shodan foi destaque na série dramática americana Mr. Robot em outubro de 2017.
(Com informações da Wikipedia sobre a Shodan)

Perguntas frequentes sobre o Banco Central do Brasil
1 – O que é o Banco Central – BACEN?
 O Banco Central do Brasil, criado pela Lei 4.595, de 1964, é uma autarquia federal, vinculada ao Ministério da Fazenda, que tem por missão assegurar a estabilidade do poder de compra da moeda e um sistema financeiro sólido e eficiente.
O Banco Central do Brasil, criado pela Lei 4.595, de 1964, é uma autarquia federal, vinculada ao Ministério da Fazenda, que tem por missão assegurar a estabilidade do poder de compra da moeda e um sistema financeiro sólido e eficiente.2 – O que faz o Banco Central?
Entre as principais atribuições do Banco Central destacam-se a condução das políticas monetária, cambial, de crédito e de relações financeiras com o exterior; a regulação e a supervisão do Sistema Financeiro Nacional (SFN) e a administração do sistema de pagamentos e do meio circulante.O Banco Central atua também como Secretaria-Executiva do Conselho Monetário Nacional (CMN) e torna públicas as Resoluções do CMN.3 – Posso obter um empréstimo ou um financiamento no Banco Central?
Não. O relacionamento financeiro do Banco Central é unicamente com as instituições financeiras. O Banco Central não é um banco comercial e não oferece empréstimos ou financiamentos, os quais podem ser obtidos com as instituições financeiras.Recomendamos que os cidadãos observem as condições contratuais e os juros incidentes sobre a operação e que procurem instituição financeira autorizada e fiscalizada pelo Banco Central, evitando fazer empréstimos com empresas desconhecidas que veiculam anúncios em jornais.Não devem ser feitos empréstimos com empresas que condicionam a liberação do dinheiro a depósitos iniciais e que anunciem em jornais oferecendo supostas facilidades e vantagens. Diversos golpes têm sido aplicados com este tipo de anúncio.4 – O Banco Central pode obrigar uma instituição a me conceder empréstimo?
Não. O Banco Central não interfere na celebração de contratos de empréstimos e financiamentos firmados entre as instituições financeiras e seus clientes, seja com relação à concessão de crédito, às condições financeiras, ao prazo da operação ou à renegociação da dívida.5 – Quais são as instituições que o Banco Central supervisiona?
São supervisionados pelo Banco Central os bancos múltiplos, bancos comerciais, bancos cooperativos, bancos de investimento, bancos de desenvolvimento, bancos de câmbio, caixas econômicas, cooperativas de crédito, sociedades de crédito, financiamento e investimento, sociedades de crédito imobiliário, sociedades de arrendamento mercantil, sociedades corretoras de câmbio, sociedades corretoras de títulos e valores mobiliários, sociedades distribuidoras de títulos e valores mobiliários, agências de fomento, companhias hipotecárias, sociedades de crédito ao microempreendedor e à empresa de pequeno porte, instituições de pagamento e administradoras de consórcio.6 – Posso registrar uma reclamação contra uma instituição autorizada a funcionar pelo Banco Central?
Sim, as reclamações podem ser apresentadas pelos clientes e usuários de produtos e serviços das instituições financeiras e demais instituições autorizadas a funcionar pelo Banco Central, a exemplo das cooperativas de crédito, instituições de pagamento e administradoras de consórcios, sempre que se verificarem indícios de descumprimento de dispositivos legais e regulamentares cuja fiscalização esteja afeta a esta Autarquia.
 As reclamações podem ser feitas por meio do Fale Conosco na internet; pelo aplicativo BC+Perto disponível para download gratuito pela App Store e na Google Play Store, pelo telefone 145, a custo de ligação local; ou ainda por correspondência. Para mais informações, acessar a página de Atendimento ao Público do Banco Central.A atuação do Banco Central com relação às reclamações terá por foco verificar o cumprimento das normas específicas de sua competência, para que as instituições supervisionadas atuem em conformidade com as leis e a regulamentação. O Banco Central não terá por objetivo principal a solução do problema individual apresentado.Para a solução de casos individuais, o cidadão deve procurar a própria instituição que lhe prestou o serviço ou comercializou o produto financeiro. Se as tentativas de solução por meio da agência ou posto de atendimento ou ainda dos serviços telefônicos ou eletrônicos de atendimento ao consumidor não apresentarem resultado, o cidadão deve procurar a ouvidoria da instituição.As ouvidorias são componentes concebidos para atuar como canal de comunicação entre essas instituições e os clientes e usuários de seus produtos e serviços, inclusive na mediação de conflitos, nos termos da Resolução 4.433, de 2015, e da Circular 3.501, de 2010.
As reclamações podem ser feitas por meio do Fale Conosco na internet; pelo aplicativo BC+Perto disponível para download gratuito pela App Store e na Google Play Store, pelo telefone 145, a custo de ligação local; ou ainda por correspondência. Para mais informações, acessar a página de Atendimento ao Público do Banco Central.A atuação do Banco Central com relação às reclamações terá por foco verificar o cumprimento das normas específicas de sua competência, para que as instituições supervisionadas atuem em conformidade com as leis e a regulamentação. O Banco Central não terá por objetivo principal a solução do problema individual apresentado.Para a solução de casos individuais, o cidadão deve procurar a própria instituição que lhe prestou o serviço ou comercializou o produto financeiro. Se as tentativas de solução por meio da agência ou posto de atendimento ou ainda dos serviços telefônicos ou eletrônicos de atendimento ao consumidor não apresentarem resultado, o cidadão deve procurar a ouvidoria da instituição.As ouvidorias são componentes concebidos para atuar como canal de comunicação entre essas instituições e os clientes e usuários de seus produtos e serviços, inclusive na mediação de conflitos, nos termos da Resolução 4.433, de 2015, e da Circular 3.501, de 2010. Em caso de insucesso, o cidadão poderá encaminhar sua demanda para os órgãos de defesa do consumidor competentes.A Secretaria Nacional de Defesa do Consumidor (SENACON) disponibiliza o site http://www.consumidor.gov.br, que permite o contato direto entre consumidores e empresas. Inicialmente, o cidadão deve verificar se a instituição financeira reclamada está cadastrada no site.
Em caso de insucesso, o cidadão poderá encaminhar sua demanda para os órgãos de defesa do consumidor competentes.A Secretaria Nacional de Defesa do Consumidor (SENACON) disponibiliza o site http://www.consumidor.gov.br, que permite o contato direto entre consumidores e empresas. Inicialmente, o cidadão deve verificar se a instituição financeira reclamada está cadastrada no site. Após o registro de sua reclamação a empresa tem até 10 dias para analisar e responder a reclamação. Em seguida, o senhor terá até 20 dias para comentar a resposta recebida, classificar a demanda como Resolvida ou Não Resolvida, e ainda indicar seu nível de satisfação com o atendimento recebido.
Após o registro de sua reclamação a empresa tem até 10 dias para analisar e responder a reclamação. Em seguida, o senhor terá até 20 dias para comentar a resposta recebida, classificar a demanda como Resolvida ou Não Resolvida, e ainda indicar seu nível de satisfação com o atendimento recebido.7 – A reclamação registrada no Banco Central tem os mesmos efeitos de uma ação na justiça?
Não. O Banco Central atua na esfera administrativa e não substitui a ação na justiça.8 – O Banco Central pode obrigar a instituição a cumprir uma decisão judicial?
Conforme esclarecido na pergunta acima, são esferas diferentes de atuação e o cumprimento de decisões judiciais deve ser buscado na esfera judicial. Cabe, portanto, ao próprio Poder Judiciário avaliar se suas decisões foram cumpridas, bem como corrigir e mandar punir eventuais descumprimentos.9 – O Banco Central pode bloquear ou desbloquear valores em contas?
Não. As determinações de bloqueio ou desbloqueio de valores são oriundas, em sua maioria, do Poder Judiciário e o Banco Central limita-se a transmitir tais determinações à rede bancária para cumprimento.O juiz pode protocolar ordens de bloqueio, desbloqueio e transferências de valores e/ou contas, solicitar informações sobre endereço, existência de ativos financeiros, saldo, extratos, comunicação de falência e extinção de falência.Para facilitar a comunicação entre o Poder Judiciário e as instituições financeiras, o Banco Central desenvolveu um sistema informatizado chamado Bacen Jud, por meio do qual as ordens judiciais são registradas e transmitidas eletronicamente para as instituições financeiras.Na verdade, os juízes poderiam enviar suas determinações diretamente às instituições financeiras, mas, pela facilidade de comunicação de que dispõe com o Sistema Financeiro, o Banco Central auxilia o Poder Judiciário na intermediação desse processo.10 – Como faço para retirar meu nome do cadastro da Serasa e do SPC?
 O cadastro da Serasa é um cadastro particular dos bancos, cuja gestão não é de competência do Banco Central.O Banco Central também não regulamenta assuntos referentes ao Serviço de Proteção ao Crédito (SPC).Cabe aos órgãos de defesa do consumidor (Procon, Prodecon, Decon) a orientação sobre o tema.
O cadastro da Serasa é um cadastro particular dos bancos, cuja gestão não é de competência do Banco Central.O Banco Central também não regulamenta assuntos referentes ao Serviço de Proteção ao Crédito (SPC).Cabe aos órgãos de defesa do consumidor (Procon, Prodecon, Decon) a orientação sobre o tema.11 – O Banco Central regula o tempo para espera na fila do banco?
Não. Veja a pergunta 3 em Atendimento bancário.12 – O Banco Central tabela o valor das tarifas cobradas pelos bancos?
O Banco Central não determina valores de tarifas. Entretanto, existem alguns serviços que os bancos devem fornecer gratuitamente. Respeitadas as proibições, cada instituição é livre para estabelecer o valor de suas tarifas.13 – Estou com restrição no Banco Central. O que fazer?
Frequentemente, o cidadão se dirige ao Banco Central alegando que, segundo lhe foi informado, há restrições em seu nome. A página do FAQ – Restrições no Banco Central foi criada com o intuito de esclarecer a respeito das informações disponíveis sobre o cidadão no Banco Central, que nem sempre representam restrições.Entre os cadastros e sistemas de informação do Banco Central, o mais abrangente é o Sistema de Informações de Crédito do Banco Central (SCR), que não é um cadastro restritivo, pois a grande maioria de seus dados referem-se a bons pagadores.Esse sistema exibe dados de todas as operações com características de crédito contratadas com instituições financeiras de clientes com responsabilidade total igual ou superior a R$200,00.Restrições em bancos podem estar relacionadas a inscrições no Serviço de Proteção ao Crédito (SPC) ou na Serasa, que não são de responsabilidade do Banco Central, conforme já esclarecido na pergunta 10.Base normativa
- Lei 4.595, de 1964
- Resolução 4.433, de 2015
- Circular 3.501, de 2010
(última atualização: Dezembro 2018)Fonte: BCBTópico: PJe Mobile – TJRN
PJe Mobile – TJRN – Download – AppStore / Google Play
[attachment file=155041]
Aplicativo Gratuito para consulta processual e acompanhamento de movimentações do PJE do TJRN, que foi desenvolvido em parceria entre o IMD/UFRN e o TJRN no programa Residência em TI Aplicada a Área Jurídica.
Funcionalidades:
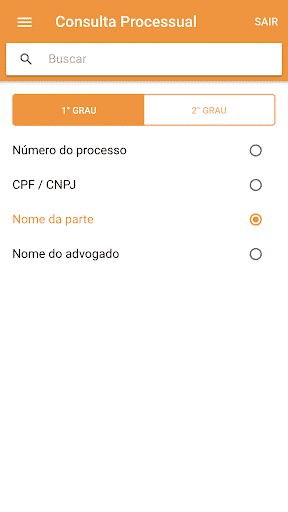
– Consulta processual por: número do processo, nome da parte, documento da parte e nome do advogado.
– Download dos documentos disponíveis no processo.
– Favoritar o processo pesquisado para facilitar consultas futuras.
– Integração com a agenda do smartphone para salvar lembretes de datas de audiências.
– Notificação de movimentação dos processos salvos nos favoritos do interessado.
– Consulta de jurisprudências.
– Consulta de pautas das unidades judiciárias.Links para download:

Aplicativo PJe Mobile - TJRN
Aplicativo PJe Mobile - TJRN
Aplicativo PJe Mobile - TJRN
Aplicativo PJe Mobile - TJRN
Aplicativo PJe Mobile - TJRN
Aplicativo PJe Mobile - TJRN
Aplicativo PJe Mobile - TJRN Após o massacre realizado na escola Raul Brasil em Suzano-SP foi a possível conexão entre os atiradores e obscuros fóruns de ódio no submundo da internet, que passaram a comemorar o feito dos jovens. Com isso, vários termos dessa rede profunda ganharam fama popular com o noticiário.Entenda quais:Chan/imageboard: é um tipo de fórum de discussão na internet. “Chan” (abreviatura do inglês “channel”, canal).Deep Web/Deep Net: São todas as páginas, lojas virtuais e fóruns de internet que estão escondidos e inacessíveis aos motores de busca, como, por exemplo, Google ou Bing.Dark Net: São páginas que estão escondidas na internet convencional e inacessíveis aos motores de busca e que, para acessar, você precisa de um tipo específico de software.Anon: Sigla para “anônimo”, e como é chamado um usuário anônimo de um chan.Board e /b/: é o nome dado às seções fixas do fórum de acordo com temas ou atividades específicas. O /b/ geralmente é o fórum destinado a assuntos aleatórios, e normalmente é o board mais acessado dos chans.CP: Sigla usada nos chans para “child porn”, pornografia infantil.Falho: Refere-se a pessoas que “falharam” na vida, atribuído a quem carece de vida social ou habilidades de comunicação interpessoal.Incel: variação do inglês involuntary celibacy (celibato involuntário). Designam pessoas – geralmente homens – caracterizadas pela virgindade indesejada e, por conta disso, uma rejeição crescente ao sexo oposto. Os incels são vertentes ou desdobramentos de grupos como os ativistas dos “direitos dos homens”.Jorge: Expressão utilizada em chans latinos para definir pessoas que fracassaram ao tentar realizar atos chocantes ou terroristas.Lulz: É uma variação da popular sigla em inglês “LOL”, que significa “Laugh Out Loud” (Rindo bem alto). Geralmente “lulz” é usado para expressar a alegria pelo sofrimento dos outros.Raid: É um tipo de campanha onde os usuários de um chan se organizam para invadir o site de um rival, redirecionando o endereço a pornografia infantil até o servidor tirá-lo do ar.Sancto/sanctum/Sanctvm: Termo em latim para “santo”, e muito usado por “incels” para glorificar os que conseguiram realizar ações criminosas.Tor: Navegador de código aberto que garante comunicação anônima e segura ao navegar na internet. Pode ser usado para ativistas se protegerem contra a censura, mas também para acessar a dark web. O Tor redireciona o tráfego de internet por uma rede de servidores voluntários e distribuídos pelo mundo.Troll: Gíria usada para os usuários de internet que costumam “causar” ou criar pegadinhas em comentários de internet e redes sociais, sem motivação aparente além da diversão própria. Muitas vezes os trolls não acreditam realmente no que estão dizendo, e escrevem conteúdo repulsivo apenas para acompanhar a reação das pessoas.(Com informações do Uol Tecnologia.)HTTPS – Hyper Text Transfer Protocol Secure (HTTPS) – O que é isso?
[attachment file=”150559″]
O protocolo de transferência de hipertexto seguro (Hyper Text Transfer Protocol Secure – HTTPS) é a versão segura do HTTP, que é o principal protocolo utilizado para enviar dados entre um navegador web e um site.
O HTTPS é criptografado para aumentar a segurança da transferência de dados. Isso é particularmente importante quando dados confidenciais são transmitidos, como fazer login em uma conta bancária, serviço de e-mail (webmail), etc.
Qualquer site que requer credenciais para efetuar login deve estar usando HTTPS. Nos navegadores modernos, como o Chrome, desenvolvido pela Google, os sites que não usam HTTPS são marcados de forma diferente dos que são.
Procure um cadeado verde na barra de URL para indicar que a página da web está segura. Os navegadores Web levam o HTTPS a sério; desde abril de 2018, a implementação do Google Chrome sinaliza todos os sites que não utilizam HTTPS como inseguros.
[attachment file=150561]
Como funciona o HTTPS?
O Hyper Text Transfer Protocol Secure usa protocolos seguros para criptografar as comunicações. Esses dois protocolos são conhecidos por Secure Socket Layer (SSL) e Transport Layer Security (TLS), o último dos quais é uma continuação do primeiro.
Através da rede mundial de computadores, esses nomes são frequentemente usados de forma intercambiável, embora os navegadores modernos usem TLS.
Em ambos os casos, o HTTPS utiliza criptografia para proteger as comunicações usando o que é conhecido como uma infra-estrutura de chave pública assimétrica. Este tipo de sistema de segurança usa duas chaves diferentes para criptografar as comunicações entre duas partes:
A chave privada:
- essa chave é controlada pelo proprietário de um website e é mantida, como o leitor fez especular, como privada. Essa chave reside em um servidor Web e é usada para descriptografar informações criptografadas pela chave pública.
A chave pública:
- essa chave está disponível para todos que desejam interagir com o servidor de maneira segura. As informações criptografadas pela chave pública só podem ser descriptografadas pela chave privada.
Por que o HTTPS é importante? O que acontece se um site não tiver HTTPS?
O HTTPS impede que os sites transmitam suas informações de uma maneira que seja facilmente visualizada por qualquer pessoa que esteja espionando por meio da Internet.
Quando as informações são enviadas através do HTTP regular, as informações são divididas em pacotes de dados que podem ser facilmente “farejados” usando software livre.
Isso torna a comunicação em um meio não seguro, como o Wi-Fi público, altamente vulnerável à interceptação.
Na verdade, todas as comunicações que ocorrem no HTTP ocorrem em texto simples, tornando-as altamente acessíveis para qualquer pessoa com as ferramentas corretas e vulneráveis a ataques intermediários.
Com o HTTPS, o tráfego é criptografado de forma que, mesmo que os pacotes sejam detectados ou interceptados, eles aparecerão como caracteres sem sentido.
Vejam o exemplo abaixo:
Antes da criptografia:
Esta é uma string de texto que é totalmente legível
Após a criptografia:
ITM0IRyiEhVpa6VnKyExMiEgNveroyWBPlgGyfkflYjDaaFf / Kn3bo3OfghBPDWo6AfSHlNtL8N7ITEwIXc1gU5X73xMsJormzzXlwOyrCs + 9XCPk63Y + z0 =
Em sites sem HTTPS, é possível que Provedores de Serviços de Internet (ISPs) ou outros intermediários injetem conteúdo em páginas da Web sem a aprovação do proprietário do site.
Isso geralmente toma a forma de publicidade, onde um provedor que busca aumentar a receita injeta publicidade paga nas páginas de seus clientes.
Sem surpresa, quando isso ocorre, os lucros para os anúncios e o controle de qualidade desses anúncios não são de forma alguma compartilhados com o dono do site.
O HTTPS elimina a capacidade de terceiros não administradores / moderadores injetarem propaganda no conteúdo no seu site, por exemplo.

Exemplo de site com HTTPS Como o HTTPS é diferente do HTTP?
Tecnicamente falando, o HTTPS não é um protocolo separado do HTTP. Está simplesmente usando a criptografia TLS / SSL sobre o protocolo HTTP.
O HTTPS ocorre com base na transmissão de certificados digitais, que verificam se um determinado provedor é quem eles dizem ser.
Quando um usuário se conecta a uma página Web, o site enviará seu certificado SSL, que contém a chave pública necessária para iniciar a sessão segura.
Os dois computadores, o cliente e o servidor, passam por um processo chamado handshake SSL / TLS, que é uma série de comunicações de ida e volta usadas para estabelecer uma conexão segura. Para aprofundar-se na criptografia e no handshake SSL / TLS, explore como um CDN usa SSL / TLS.

Créditos: weerapatkiatdumrong / iStock Como um site começa a usar o HTTPS?
Muitos provedores de hospedagem de sites e outros serviços oferecem certificados HTTPS por uma taxa. Esses certificados costumam ser compartilhados entre muitos clientes. Certificados mais caros estão disponíveis, que podem ser registrados individualmente em determinadas propriedades da web.
Todos os sites que usam o Cloudflare recebem HTTPS gratuitamente usando um certificado compartilhado. A criação de uma conta gratuita garantirá que uma propriedade da Web receba proteção HTTPS continuamente atualizada. Você também pode adquirir um SSL com a Juristas Certificação Digital. (Com informações da Cloud Flare).
Saiba mais:
O que é Raspagem / Extração de Dados (Data Scraping) ?

Créditos: ipopba / iStock O Data Scraping, em sua forma mais comum, refere-se a uma técnica na qual um programa de computador extrai dados gerados por um outro programa ou computador.
A coleta de dados, no mais das vezes, se manifesta no processo de extração de dados na Web, o processo de usar um aplicativo para extrair informações valiosas de um site como o próprio buscador Google.
Por que copiar dados do site?

Créditos: Stas_V / iStock Em geral, as empresas não querem que seu conteúdo exclusivo seja baixado e reutilizado para fins não autorizados. Como resultado, as mesmas não expõem todos os dados por meio de uma API (Application Program Interface) ou por outro recurso de fácil acesso.
Scrapers, por outro lado, estão interessados em obter dados do site, independentemente de qualquer tentativa de limitar o acesso. Como resultado, existe um jogo de gato e rato entre o Web Scraping e várias estratégias de proteção de conteúdo, com cada um tentando superar o outro.
O processo de extração da Web é bastante simples, embora a implementação possa ser complexa. A captura da Web ocorre em 3 etapas:
Primeiro, o pedaço de código usado para extrair as informações, que chamamos de raspador, envia uma solicitação HTTP GET para um site específico.
Quando o site responde, o Scraper analisa o documento HTML para um padrão específico de dados.
Depois que os dados são extraídos, eles são convertidos em qualquer formato específico criado pelo autor do Scraper.
Raspadores podem ser projetados para vários propósitos, como:
Recolha de conteúdos
- o conteúdo pode ser retirado do website para poder replicar a vantagem única de um determinado produto ou serviço que depende do conteúdo. Como exemplo, um produto como o site Yelp depende de revisões; um concorrente pode coletar todo o conteúdo de revisão do Yelp e reproduzir o conteúdo em seu próprio site, fingindo que o conteúdo é original.
Captura de preços
- ao coletar dados de preços, os concorrentes podem agregar informações sobre sua concorrência. Isso pode permitir que formem uma vantagem única.
Raspagem / Captura de contatos
- muitos sítios virtuais contêm endereços de e-mail e números de telefone em texto sem formatação. Ao capturar locais como um diretório de funcionários online, um Scraper pode agregar detalhes de contato para listas de mala direta, chamadas de robô (bot) ou tentativas mal-intencionadas de engenharia social. Esse é um dos principais métodos usados pelos spammers e golpistas para encontrar novos alvos.
Como é que o Web Scraping pode ser mitigado?

Créditos: maciek905 / iStock A realidade é que não há como impedir a captura da web; com tempo suficiente, um Web Scraper repleto de recursos pode extrair todo um site voltado para o público, página por página.
Isso é fruto do fato de que qualquer informação visível dentro de um navegador da Web pode ser baixada para ser tratada. Em outras palavras, todo o conteúdo que um visitante pode visualizar deve ser transferido para a máquina do visitante, e qualquer informação que um visitante possa acessar pode ser copiada.
Esforços podem ser feitos para limitar a quantidade de raspagem da web que pode ocorrer. Existem 3 métodos principais de limitar a exposição a esforços de raspagem de dados:
Solicitações de limite de taxa:

para um “internauta humano” clicar em uma série de páginas Web em um sítio virtual, a velocidade de interação com o site é bastante previsível; por exemplo, você nunca terá um humano navegando por 100 (cem) páginas por segundo. Os computadores, por outro lado, podem fazer inúmeras solicitações de ordens de magnitude mais rápidas do que um ser humano, e os raspadores de dados novatos podem usar técnicas de raspagem não-rotuladas para tentar extrair os dados de um site inteiro muito rapidamente. Ao limitar o número máximo de requisições que um determinado endereço IP (Internet Protocol) é capaz de realizar em uma determinada janela de tempo, os sites podem se proteger de solicitações de exploração e limitar a quantidade de dados que podem ser extraídos em uma determinada janela.
Modifique a marcação HTML em intervalos regulares:
- o software de extração de dados depende da formatação consistente para percorrer efetivamente o conteúdo do site e analisar, bem como salvar os dados úteis. Um método de interromper este fluxo de trabalho é alterar regularmente os elementos da marcação HTML para que a extração consistente se torne mais complexa. Encaixando elementos HTML ou alterando outros aspectos da marcação, esforços simples de coleta de dados serão impedidos ou frustrados. Para alguns sites, cada vez que uma página Web é processada, algumas formas de modificações de proteção de conteúdo são randomizadas e implementadas, enquanto outras irão alterar seu site ocasionalmente para evitar esforços de coleta de dados a longo prazo.
Use CAPTCHAs para solicitantes de alto volume:
-

Créditos: BeeBright / iStock além de utilizar uma solução de limitação de taxa, outra etapa útil na desaceleração dos extratores de conteúdo é a exigência de que um visitante do site responda a um desafio que é difícil para um computador superar. Embora um ser humano possa responder de forma razoável ao desafio, um navegador sem ser programado para desafios CAPTCHAs para extração de dados provavelmente não pode, e certamente não irá obter sucesso em muitos desafios. Outros desafios baseados em javascript podem ser implementados para testar a funcionalidade do navegador.

Créditos: domoskanonos / iStock Outro método menos comum de mitigação exige a incorporação de conteúdo dentro de objetos de mídia, como imagens. Como o conteúdo não existe em uma cadeia de caracteres, a cópia do conteúdo é muito mais complexa, exigindo reconhecimento ótico de caracteres (OCR – Optical Character Recognition) para extrair os dados de um arquivo de imagem.
Isso também pode fornecer um obstáculo aos usuários da Web que precisam copiar conteúdo, como um endereço ou número de telefone, de um site, em vez de memorizá-lo ou digitá-lo.
Como a web scraping é interrompida completamente?
A única maneira de impedir o Web Scraping de conteúdo é evitar colocar o conteúdo em um site completamente. Métodos mais realistas incluem ocultar conteúdo importante por trás da autenticação do usuário, onde é mais fácil rastrear usuários e destacar comportamentos nefastos.
Qual é a diferença entre a coleta de dados e o rastreamento de dados?
O rastreamento basicamente se refere ao processo que os grandes mecanismos de pesquisa, como o Google, Yahoo, Bing, Yandex, entre outros, realizam quando enviam seus robôs rastreadores, como o Googlebot da Google, para a rede para indexar o conteúdo da Internet.
A raspagem, por outro lado, é tipicamente estruturada especificamente para extrair dados de um site específico.
Aqui estão três das práticas em que um scraper se envolverá e que são diferentes do comportamento do rastreador da web:
Os Scrapers fingirão ser navegadores da web, em que um rastreador indicará seu objetivo e não tentará enganar um website, fazendo-o pensar que é algo que não é.
Às vezes, os raspadores realizam ações avançadas, como o preenchimento de formulários ou o envolvimento em comportamentos para alcançar determinada parte do site. Crawlers não.
Os Scrapers geralmente não levam em consideração o arquivo robots.txt, que é um arquivo de texto que contém informações especificamente projetadas para informar aos rastreadores da Web quais dados analisar e quais áreas do site devem ser evitadas. Como um raspador foi projetado para extrair conteúdo específico, ele pode ser projetado para extrair conteúdo explicitamente marcado para ser ignorado.
O Sistema WAF de empresas de CDN como a Cloudflare, Gocache, entre outros que podem ajudar a limitar o limite e filtrar os raspadores, protegendo o conteúdo exclusivo e impedindo que bots abusem de um site na web. (Com informações da Cloud Flare)
O novo Google Chrome marcará todos os sites HTTP como não seguros. Você já está preparado?
[attachment file=150438]
O Google é fã de HTTPS há muito tempo e tem adotado medidas incrementais para direcionar os sites para melhorar sua segurança – esta última etapa é a mais alta.
Ao implementar a segurança adequada, os sítios virtuais podem reduzir uma variedade de atividades nefastas, o que, por sua vez, ajuda o Google a direcionar pessoas para sites legítimos.
Esta é uma das razões pelas quais o Google usa o HTTPS como um fator de qualidade em como eles retornam os resultados da pesquisa; quanto mais seguro for o site, menor será a probabilidade de o visitante cometer um erro ao clicar no link fornecido pelo Google.
Desde o mês de julho de 2018, com o lançamento do Chrome 68, todo o tráfego HTTP não protegido será sinalizado na barra de URL como “não seguro”.
Isso significa que, para todos os sites sem um certificado SSL válido, esta notificação será exibida.
[attachment file=150439]
Etapas incrementais do Google para o HTTPS
Para aqueles que têm seguido a adoção de HTTPS exigida pelo Google, essa atualização provavelmente não é surpreendente.
O Google planejou três etapas na adoção incremental de demarcação de HTTPS e mencionou a meta final com o primeiro lançamento.
No ano de 2016, o provedor de buscas Google anunciou que começaria a sinalizar sites HTTP comuns que coletam informações de cartão de crédito ou coletam senhas.
Esses sinalizadores, uma modificação na barra de URL, foram configurados para começar no mês de janeiro do ano de 2017 com o lançamento do Chrome 56.
O anúncio deixou claro que o objetivo de longo prazo do Google era sinalizar todos os sites HTTP.
A etapa em seguida ocorreu no mês de outubro de 2017 com o lançamento do Chrome 62. Nesta versão, no momento em que um usuário começou a inserir dados em um site inseguro, o Chrome notifica novamente o internauta na barra onde se escreve a URL do site.
Com essa mesma atualização, o escopo do sinalizador de segurança foi expandido para o modo de navegação anônima; desde então, todo o tráfego não-HTTPS na navegação anônima é marcado como não seguro.
A atualização de julho de 2018 é a última etapa da sequência, destacando em termos inequívocos o desejo do provedor de buscas Google de ter todos os sites protegidos por HTTPS.
Se você controlar qualquer propriedade de um sítio virtual que não esteja usando criptografia, agora é um excelente momento para fazer as alterações.
Se você acredita que existem algumas desvantagens para o HTTPS que superam a necessidade de fazer a alteração, continue a ler este texto.
[attachment file=150440]
Informações equivocadas sobre o HTTPS
A razão pela qual o provedor Google lançou as atualizações do HTTPS ao longo do tempo, em vez de todas de uma vez, provavelmente é porque muitos sítios demoraram a adotar conexões seguras. Para descobrir por que este é o caso, temos que olhar para a história.
Quando o HTTPS começou a ser implementado, a implementação adequada era difícil, lenta e cara; era difícil implementar corretamente, diminuía as solicitações da Internet e aumentava os custos, exigindo serviços de certificados caros.
Nenhum desses impedimentos permanece verdadeiro, mas ainda existe um medo persistente para muitos proprietários de sites, o que tem impedido que alguns dêem o salto para uma melhor segurança. Vamos explorar alguns dos mitos sobre o HTTPS.
“Não lidei com informações confidenciais no meu site, por isso não preciso de HTTPS”.
Um motivo comum pelo qual os sites não implementam a segurança é porque acham que é um exagero para seus objetivos. Afinal, se você não está lidando com dados confidenciais, quem se importa se alguém está bisbilhotando?
Existem algumas razões pelas quais essa é uma visão excessivamente simplista sobre segurança na web. Por exemplo, alguns provedores de serviços de Internet injetam publicidade em sites publicados por HTTP.
Esses anúncios podem ou não estar em consonância com o conteúdo do site e podem ser potencialmente ofensivos, além do fato de o provedor do site não ter participação criativa ou parcela da receita. Esses anúncios injetados não são mais possíveis depois que um site é protegido.
Navegadores modernos agora limitam a funcionalidade de sites que não são seguros. Recursos importantes que melhoram a qualidade do site agora exigem HTTPS.
Geolocalização, notificações push e os trabalhadores de serviço necessários para executar Aplicativos da Web Progressivos (PWAs) exigem segurança reforçada. Isso faz sentido; Dados como a localização de um usuário são confidenciais e podem ser usados para fins nefastos.
“Não quero prejudicar o desempenho do meu site aumentando meus tempos de carregamento da página”
O desempenho é um fator importante na experiência do usuário e na forma como o Google retorna resulta em pesquisa. Com o tempo, isso se torna ainda mais verdadeiro; em julho, o Google começou a modificar os rankings de busca de sites móveis com base no desempenho móvel.
Compreensivelmente, o aumento da latência é algo a ser levado a sério. Felizmente, ao longo do tempo, melhorias foram feitas no HTTPS para reduzir a sobrecarga de desempenho necessária para configurar uma conexão criptografada.
Quando ocorre uma conexão HTTP, há várias viagens que a conexão precisa fazer entre o cliente que está solicitando a página da Web e o servidor. Além da latência normal associada a um handshake TCP (mostrado em azul abaixo), um handshake TLS / SSL adicional (mostrado em amarelo) deve ocorrer para usar HTTPS.
As melhorias podem ser implementadas para reduzir a latência total da criação de uma conexão SSL, incluindo a retomada da sessão TLS e o início falso de TLS.
Utilizando a retomada da sessão, um servidor pode manter uma conexão ativa por mais tempo, retomando a mesma sessão para solicitações adicionais. Manter a conexão ativa economiza tempo gasto na renegociação da conexão quando o cliente exige uma busca de origem não armazenada em cache, reduzindo o RTT total em 50%.
Outra melhoria na velocidade com que um canal criptografado pode ser criado é implementar um processo chamado início falso de TLS, que reduz a latência enviando os dados criptografados antes que o cliente termine a autenticação. Para mais informações, explore como o TLS / SSL funciona em um CDN (Cloud Delivery Network).
Por derradeiro, mas não menos importante, o HTTPS desbloqueia aprimoramentos de desempenho usando HTTP/2 que permitem fazer coisas interessantes, como push e multiplexing de servidor, o que pode otimizar bastante o desempenho de solicitações HTTP. No total, há um benefício de desempenho significativo para fazer a troca.
“É muito caro implementar o HTTPS”
A certa altura, isso pode ter sido verdade, mas agora o custo não é mais uma preocupação; Algumas empresas oferecem aos sites a capacidade de criptografar o trânsito gratuitamente.
[attachment file=150441]
Eu vou perder o ranking de pesquisa ao migrar meu site para HTTPS
Há riscos associados à migração de sites, e, de maneira inadequada, um impacto negativo no SEO é possível. As armadilhas potenciais incluem tempo de inatividade do site, páginas da Web não rastreadas e penalização para duplicação de conteúdo quando duas cópias do site existem ao mesmo tempo.
Dito isso, os sites podem ser migrados com segurança para HTTPS seguindo as práticas recomendadas.
Duas das práticas de migração mais importantes são:
1) usando redirecionamentos 301 e 2) o posicionamento correto de tags canônicas. Ao usar redirecionamentos do servidor 301 no site HTTP para apontar para a versão HTTPS, um site informa ao Google para ir para o novo local para todos os propósitos de pesquisa e indexação.
Ao colocar tags canônicas apenas no site HTTPS, os rastreadores, como o Googlebot, saberão que o novo conteúdo seguro deve ser considerado canônico daqui para frente.
Se você tiver um grande número de páginas e estiver preocupado com o fato de o rastreamento demorar muito, entre em contato com o Google e informe o volume de tráfego que deseja colocar no seu website.
Os engenheiros de rede aumentarão a taxa de rastreamento para ajudar a analisar seu site rapidamente e indexá-lo. (Com informações da Cloud Flare)
Adquira o seu SSL com a Juristas Certificação Digital através deste WhatsApp (83)993826000, pelo email [email protected], pelo formulário abaixo ou pela loja virtual.
[gravityform id=”6″ title=”true” description=”true” ajax=”true”]
O que é TLS (Transport Layer Security)?
[attachment file=150434]
O Transport Layer Security, ou TLS, nada mais é que um protocolo de segurança amplamente adotado, projetado para facilitar a privacidade e a segurança dos dados nas comunicações realizadas por meio da rede mundial de computadores.
A principal utilidade do TLS é proteger a comunicação entre aplicativos e servidores Web, como navegadores que carregam um sítio virtual. O Transport Layer Security ainda pode ser utilizado para proteger outros tipos de comunicações como e-mail (correio eletrônico), mensagens e voz sobre IP (VOIP).
Neste texto, vamos nos concentrar na função do Transport Layer Security (TLS) na segurança de aplicativos Web.
O TLS foi proposto pela IETF (Internet Engineering Task Force), uma organização internacional de padrões e a sua primeira versão foi publicada no ano 1999. A versão mais recente é a TLS 1.2, publicada no ano de 2008; A versão 1.3 está atualmente muito próxima da publicação e já está sendo utilizada por alguns aplicativos Web.
Qual é a diferença entre o TLS e o SSL?

Créditos: 8vFanI / iStock O TLS evoluiu de um protocolo de segurança anterior, chamado Secure Socket Layer Security (SSL), desenvolvido pela empresa Netscape. O TLS versão 1.0 na verdade começou o desenvolvimento como SSL versão 3.1, entretanto o nome do protocolo foi modificado antes da publicação para indicar que ele não estava mais associado a Netscape.
Por esta razão histórica, os termos TLS e SSL são usados às vezes de maneira intercambiável.
Qual é a diferença entre o TLS e o HTTPS?
HTTPS nada mais é que uma implementação de criptografia TLS sobre o popular protocolo HTTP, que é muito utilizado por todos os sites, bem como por alguns outros serviços da web. Pode ser dito que qualquer site que utilize HTTPS está, no entanto, empregando segurança TLS.
Por que você deve usar o TLS?
A criptografia decorrente do TLS pode ajudar a proteger aplicativos da Web contra ataques, como violações de dados e ataques DDoS. Além disso, o HTTPS protegido por TLS está rapidamente se tornando uma prática padrão para sites. Por exemplo, o navegador Chrome da Google está reprimindo sites que não utilizem HTTPS e usuários comuns da Internet estão começando a ficar mais cautelosos com sites que não apresentam o ícone de cadeado HTTPS.
Como o TLS funciona?
A segurança da camada de transporte é implementada na camada de aplicação do modelo OSI, o que significa que ela pode ser usada sobre um protocolo de segurança da camada de transporte como o TCP. Existem três componentes principais para o TLS: Criptografia, Autenticação e Integridade.
Criptografia: oculta os dados sendo transferidos de terceiros.
Autenticação: garante que as partes que trocam informações sejam quem elas afirmam ser.
Integridade: verifica se os dados não foram falsificados ou adulterados.
Uma conexão TLS é iniciada utilizando uma sequência conhecida como handshake TLS. O handshake TLS começa com uma troca syn / sync ack / ack semelhante à usada no TCP e estabelece um conjunto de códigos para cada comunicação.
A suíte cypher é um conjunto de algoritmos que especifica detalhes como qual chave de criptografia compartilhada será usada para aquela sessão específica.
O TLS é capaz de definir as chaves de criptografia correspondentes em um canal não criptografado graças a uma tecnologia conhecida como criptografia de chaves públicas.
O handshake também lida com autenticação, que geralmente consiste em o servidor comprovar sua identidade para o cliente. Isso é feito usando chaves públicas.
As chaves públicas são chaves de criptografia que usam criptografia unidirecional, o que significa que qualquer pessoa pode desembaralhar a chave para garantir sua autenticidade, no entanto, apenas o remetente original pode gerar a chave.
Depois que os dados são criptografados e autenticados, eles são assinados com um código de autenticação de mensagem (MAC). O destinatário pode então verificar o MAC para garantir a integridade dos dados.
Isso é como um selo à prova de violação encontrada em um frasco de aspirina; o consumidor sabe que ninguém adulterou o medicamento porque o selo está intacto quando o compra.
Como o TLS afeta o desempenho dos aplicativos Web?
Por força do processo complexo envolvido na configuração de uma conexão TLS, algum tempo de carregamento e poder computacional devem ser gastos. O cliente e o servidor devem se comunicar três vezes antes de qualquer dado ser transmitido, e isso consome preciosos milissegundos de tempo de carregamento para aplicativos da Web, além de alguma memória para o cliente e o servidor.
Felizmente, existem tecnologias que ajudam a mitigar o atraso criado pela handshake TLS. Um é o TLS False Start, que permite que o servidor e o cliente iniciem a transmissão de dados antes que a handshake TLS seja concluída.
Outra tecnologia para acelerar o Transport Layer Security é a Reinicialização de Sessões TLS, que permite que clientes e servidores que já se comunicaram usem um aperto de mão abreviado.
Essas melhorias ajudam a tornar o Transport Layer Security um protocolo muito rápido que não deve afetar visivelmente os tempos de carregamento. Quanto aos custos computacionais associados ao TLS, eles são praticamente insignificantes pelos padrões atuais.
Por exemplo, quando o Google moveu toda a plataforma do Gmail para HTTPS em 2010, não houve necessidade de ativar nenhum hardware adicional. A carga extra em seus servidores como resultado da criptografia Transport Layer Security foi inferior a 1% (um por cento). (Com informações da CloudFlare)
Adquira o seu SSL / TLS com na loja virtual da Juristas Certificação Digital. Entre em contato conosco via WhatsApp – 83 993826000 ou pelo formulário abaixo.
[gravityform id=”6″ title=”true” description=”true” ajax=”true”]
[attachment file=150427]
O que é “Advogado“?
Advogado (substantivo masculino)
1.Advogado é uma pessoa habilitada a prestar assistência profissional em assunto jurídico, defendendo extrajudicial ou judicialmente os interesses do seu constituinte (cliente).
2.POR EXTENSÃO
Advogado é aquele que também intercede, que medeia; mediador, intercessor.
“nas brigas da família, o patriarca ou a matriarca agia como um a.”3.POR EXTENSÃO
Advogado também é a pessoa que patrocina ou protege alguém ou uma causa; patrono, defensor.
“é um a. da literatura de cordel”Origem do termo advogado
⊙ ETIM lat. advocātus,i ‘patrono, defensor procurador da causa etc.’
Advogado (mais significados)
adjetivo
que se advogou.
“causa a.”Origem
⊙ ETIM lat. advocātus,a,um ‘que foi convocado’, part.pas. de advocāre ‘chamar a si, convocar, convidar etc.’Sinônimos de Advogado
Advogado é sinônimo de:
Definição de Advogado

Créditos: Deagreez / iStock Classe gramatical: adjetivo e substantivo masculino
Flexão do verbo advogar no: particípio
Separação silábica: ad-vo-ga-do
Plural: advogados
Feminino: advogadaMais informações sobre “Advogado”
Advogado nada mais é que um profissional liberal, graduado (bacharel ou licenciado) em direito (ciências jurídicas) e autorizado pelas instituições competentes de cada país a exercer o jus postulandi, ou melhor, a representação dos legítimos interesses das pessoas físicas ou jurídicas em juízo ou fora dele (judicial ou extrajudicialmente), quer entre si, quer ante o Estado.
O advogado constitui uma peça importantíssima para a administração da Poder Judiciário e instrumento essencial para garantir a defesa dos interesses das partes em juízo.
Assim, pode ser dito que advocacia não é apenas uma profissão, mas, um munus publicum, ou melhor, um encargo público, já que, embora não seja agente estatal, compõe um dos elementos da administração democrática do Poder Judiciário.
Pode-se decompor a atuação da advogacia em 7 (sete) funções jurídicas básicas:
- Assessoria jurídica (interna ou externa, inclusive no apoio negocial, em tempo real);
- Consultoria jurídica (externa ou interna – Outside Counsel – In-House Counsel);
- Procuradoria jurídica;
- Auditoria jurídica;
- Controladoria jurídica;
- Planejamento jurídico;
- Ensino jurídico.
- Entre outras.
Desta forma, os(as) advogados(as) atuam, além de prestar consultoria jurídica, que consiste na verificação de negócios importantes sob o aspecto legal, para prevenir eventuais litígios futuros, seja “auditando” ou “controlando”, para se usar a terminologia da ciência da administração. O causídico também pode ser especialista em uma área (ramo) do Direito, como o advogado criminalista, civilista, contratualista, entre outros, por exemplo.
O vocábulo deriva da expressão em latim ad vocatus que significa o que foi chamado, que, no Direito romano, designava a terceira pessoa que o litigante chamava perante o juízo para falar a seu favor ou defender o seu interesse.
No mais das vezes, a atividade do advogado é unificada, exceto no Reino Unido, em que há divisão entre barristers e solicitors: os primeiros atuam nos tribunais superiores, ao passo que os últimos advogam nos tribunais e juízos inferiores e lidam diretamente com os constituintes.
O patrono dos advogados em todo o mundo é Santo Ivo, segundo a crença da Igreja Católica.
(Com informações do Feedback do Google, do Dicio e da Wikipedia)
O que é SSL (Secure Socket Layers)?

Créditos: bluebay2014 / iStock SSL (Secure Sockets Layer) nada mais é que a tecnologia padrão de segurança para estabelecer uma conexão criptografada entre um servidor Web e um navegador.
Esse link garante que todos os dados transmitidos entre o servidor Web e os navegadores permaneçam privados e íntegros.
Pode ser dito que, o SSL é um padrão da indústria e é utilizado por milhões de sites na proteção de suas transações on-line com seus clientes. O Google mesmo exige a utilização de SSL nos servidores dos sítios virtuais, sob pena deles afirmarem que o site não é confiável.
Para poder criar uma conexão SSL, um servidor Web requer um Certificado SSL. Quando você optar por ativar o SSL em seu servidor Web, será solicitado que você responda a várias perguntas sobre a identidade do seu sítio virtual, vem como da sua empresa. Seu servidor Web passará a ter duas chaves criptográficas – uma chave privada e uma chave pública.
A chave pública não precisa ser secreta e é colocada em uma solicitação de assinatura de certificado (CSR) – um arquivo de dados que também contém seus detalhes. Você deve então enviar o CSR.
Durante o processo de solicitação do Certificado SSL, a Autoridade de Certificação validará seus detalhes e emitirá um Certificado SSL contendo seus dados e permitindo que você use SSL.
Seu servidor Web corresponderá ao seu certificado SSL emitido à sua chave privada e poderá estabelecer uma conexão criptografada entre o site e o navegador do seu cliente.
As complexidades do protocolo SSL permanecem invisíveis para seus clientes. Em vez disso, seus navegadores fornecem um indicador chave para que eles saibam que estão atualmente protegidos por uma sessão criptografada por SSL – o ícone de cadeado no canto superior direito, clicando no ícone de cadeado exibe seu Certificado SSL e os detalhes sobre ele. Todos os Certificados SSL são emitidos para empresas ou indivíduos legalmente responsáveis pelo Servidor WEB.
Normalmente, um Certificado SSL (Secure Socket Layers) conterá seu nome de domínio, nome de sua empresa, seu endereço, sua cidade, seu estado e seu país. Também conterá a data de expiração do Certificado e os detalhes da Autoridade Certificadora responsável pela emissão do Certificado.
Quando um navegador se conecta a um site seguro, ele recupera o certificado SSL do site e verifica se ele não expirou, se foi emitido por uma autoridade de certificação e se está sendo usado pelo site para o qual foi emitido .
Se falhar em qualquer uma dessas verificações, o navegador exibirá um aviso para o usuário final informando que o site não está protegido por SSL.
Não deixe de visitar o site AR Juristas e Portal Juristas para obter alguns ótimos serviços e ferramentas para ajudar na implementação do ssl em seu site ou se você quiser examinar os certificados ssl de outros sites, bem como para adquirir o seu certificado SSL agora mesmo. (Com informações do site SSL.com)
Tópico: Telefones da Air France
Telefones da Air France
A Air France faz todo o possível para responder às suas perguntas e atender aos seus pedidos.Não deixe de usar nossa ferramenta de busca ou consultar as seções abaixo.VENDAS POR TELEFONE AIR FRANCE
Para reservar, obter nosso programa em tempo real ou fazer perguntas, você pode entrar em contato com nossos atendentes diretamente por telefone pelo:
+55 11 3878 8360*
de 2a a 6a feira das 8h às 20h, sábados e domingos das 9h às 15h
AGÊNCIAS AIR FRANCE NO BRASIL
RIO DE JANEIRO
Av. 20 de Janeiro s/n – TERMINAL 2 – 2º Andar (Embarque)
Cep: 21941-570
Ilha do Governador – RJ
CNPJ 33013988/00018-20Até 27/10/18: Diariamente das 08h00 às 11h00, das 12h10 às 15h00 e das 18h10 às 21h00.A partir de 28/10/18: Diariamente das 08h00 às 12h00, das 13h15 às 15h30 e das 17h30 às 20h05.A partir de 04/11/18: Diariamente das 09h00 às 13h00, das 14h10 às 16h30 e das 18h30 às 21h05.RECLAMAÇÕES DE BAGAGENS
BAGAGENS NÃO ENTREGUES NA CHEGADA
A sua bagagem não lhe foi entregue na chegada ao aeroporto? Lamentamos imensamente e faremos todos os esforços para que ela lhe chegue o mais rápido possível. Encontre todas as informações sobre o que fazer em nossa seçãoIncidentes com bagagens .Caso seu aeroporto de destino se encontra na França metropolitana: você pode fazer a sua declaração no serviço de Bagagens da Air France no aeroporto ou preencher o formulário da declaração online nas 48 horas seguintes à sua chegada.Se seu aeroporto de destino não se encontra na França metropolitana: por favor comunique logo que possível o atraso da sua bagagem ao serviço de bagagens da Air France no aeroporto. Nós iremos lhe entregar um documento (chamado “Property Irregularity Report – PIR”) que deve obrigatoriamente ser preenchido antes de sair do aeroporto. Ser-lhe-á comunicado um número de dossiê. Por favor conserve este número para poder acompanhar sua comunicação.Sua bagagem foi danificada ou não lhe foi entregue na chegada? Você esqueceu algum objeto a bordo, no aeroporto ou num balcão de check-in?OUTRAS RECLAMAÇÕES
Vôo atrasado ou cancelado, dificuldade no aeroporto, reclamação sobre sua viagemPOR CARTA
Atendimento ao Cliente AIR FRANCE – KLM Brasil
CAIXA POSTAL 02 Barueri
SP Brasil CEP 06402-970Informe sempre seu endereço completo, incluindo o CEP. Para agilizar um eventual reembolso,favor informar, seus dados bancários (nome do Banco, agência e número da conta) e o CPF do titular no campo mensagem livre do formulário.
Atenção: os documentos originais (faturas, cartões de embarque) deverão ser enviados juntos com a sua carta.
POR TELEFONE
SAC e acompanhamento de sua solicitação : 0800 888 7000 – Atendimento das 8h ás 18h, 7 dias por semana
ATENDIMENTO A DEFICIENTE AUDITIVO
Baixe o aplicativo Hangout no seu computador ou aparelho móvel e entre em contato via chat através do endereçoFLYING BLUE
Você perdeu seu cartão Flying Blue? Faltam milhas na sua conta? Seus dados não estão atualizados? O departamento Flying Blue responde a todas as suas dúvidas.[attachment file=”149499″]
United Airlines
Diversas publicações envolvendo a United Airlines:
- STJ confirma aplicação da Convenção de Montreal em caso que envolve indenização por extravio de carga em transporte aéreo internacional
- Tratamento distinto para consumidor VIP não fere isonomia entre passageiros
- Ferramenta do Google usa inteligência artificial para detectar voos atrasados
- United Airlines Inc – Jurisprudências

 O
O  As reclamações podem ser feitas por meio do Fale Conosco na internet; pelo aplicativo BC+Perto disponível para download gratuito pela App Store e na Google Play Store, pelo telefone 145, a custo de ligação local; ou ainda por correspondência. Para mais informações, acessar a página de
As reclamações podem ser feitas por meio do Fale Conosco na internet; pelo aplicativo BC+Perto disponível para download gratuito pela App Store e na Google Play Store, pelo telefone 145, a custo de ligação local; ou ainda por correspondência. Para mais informações, acessar a página de  Em caso de insucesso, o cidadão poderá encaminhar sua demanda para os órgãos de defesa do consumidor competentes.
Em caso de insucesso, o cidadão poderá encaminhar sua demanda para os órgãos de defesa do consumidor competentes. Após o registro de sua reclamação a empresa tem até 10 dias para analisar e responder a reclamação. Em seguida, o senhor terá até 20 dias para comentar a resposta recebida, classificar a demanda como Resolvida ou Não Resolvida, e ainda indicar seu nível de satisfação com o atendimento recebido.
Após o registro de sua reclamação a empresa tem até 10 dias para analisar e responder a reclamação. Em seguida, o senhor terá até 20 dias para comentar a resposta recebida, classificar a demanda como Resolvida ou Não Resolvida, e ainda indicar seu nível de satisfação com o atendimento recebido. O cadastro da Serasa é um cadastro particular dos bancos, cuja gestão não é de competência do Banco Central.
O cadastro da Serasa é um cadastro particular dos bancos, cuja gestão não é de competência do Banco Central. O Banco Central também não regulamenta assuntos referentes ao Serviço de Proteção ao Crédito (SPC).
O Banco Central também não regulamenta assuntos referentes ao Serviço de Proteção ao Crédito (SPC).